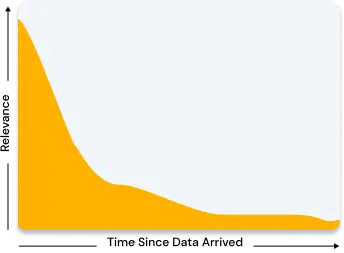
In our continuous pursuit to improve the security and user experience of our platform, we are thrilled to announce a significant upgrade: the adoption of Single Sign-On (SSO) and User Federation. This innovation underscores our commitment to delivering a seamless, secure, and efficient experience for our users. Why Single Sign-On and User Federation? In the […]
Read Full Article